
Six AI Terms UXers Should Know
Clear and simple definitions of essential concepts
As members of UX teams, we have a responsibility to understand the inner workings of our apps and sites. Yet when it comes to building products and services that rely on artificial intelligence, this can prove challenging; while AI is not a new field in computer science (it formalized in the 1950s), it’s a new frame of reference for those of us practicing UX design and content strategy for consumer products.
At Google, we’re committed to providing clear explanations on how AI systems work for both users and the general public. Depending on who you are—a novice, an expert, a researcher, a developer, a designer, a content strategist, or a policy advocate—the expectation of how the same AI terms might be used or applied is going to be very different. When everyone is on the same page (of the dictionary, if you will), we can have a shared, specific understanding of certain key terms used by ML and AI practitioners. This can help UX teams better communicate not only how to address user needs, but also build users’ trust in AI systems by explaining how these systems work clearly and simply.
A foundational vocabulary
To land on a foundational vocabulary for UXers, we looked back at the inaugural set of posts from our People + AI Research collection, to see which AI terms showed up the most. We also surveyed dozens of designers across Google: on what ML means to them, and how they’d define ML in their own words. This helped us compile a basic AI vocabulary list from which we identified six terms that are commonly used (and often misinterpreted), by UX designers, researchers, and content strategists. Here, we define them in a clear and simple way.

Artificial intelligence (AI)
The science of making machines intelligent, so they can recognize patterns and get really good at helping people solve specific challenges or sets of challenges.
Artificial intelligence is in use when a computer program makes a decision on a prediction—this could be through straightforward rule-based systems or heuristic methods, such as “if rain, then umbrella.” In machine learning (see below) on the other hand, the decisions are learned.

Machine learning (ML)
A subfield of artificial intelligence that comprises techniques and methods to develop AI, by getting computer programs to do something without programming super-specific rules.
There are many ways to get a computer program to learn something. Most relevant to our list is supervised learning, in which the program learns to make predictions—like your commute time—from hundreds of thousands of examples. Other popular approaches are unsupervised, semi-supervised, and reinforcement learning, but we’ll leave those for another day (or you can learn the technical details on your own with our Machine Learning Glossary for developers).
ML model
A bunch of specialized, connected, mathematical functions. Together they represent the steps an intelligent machine will take to arrive at a decision.
By recognizing traffic patterns and adapting to unique situations, an ML model is able to estimate how soon you may arrive at your destination, assuming you follow the same route. Sometimes ML models are conflated with algorithms or neural networks. Algorithms are more general-purpose, almost recipe-like computing procedures, while neural networks, are just one kind of ML model. Fun fact: They’re called neural networks because they’re modeled after neurons in the human brain. Neurons transmit nerve impulses and are responsible for human learning, creativity, and conceptual prowess!
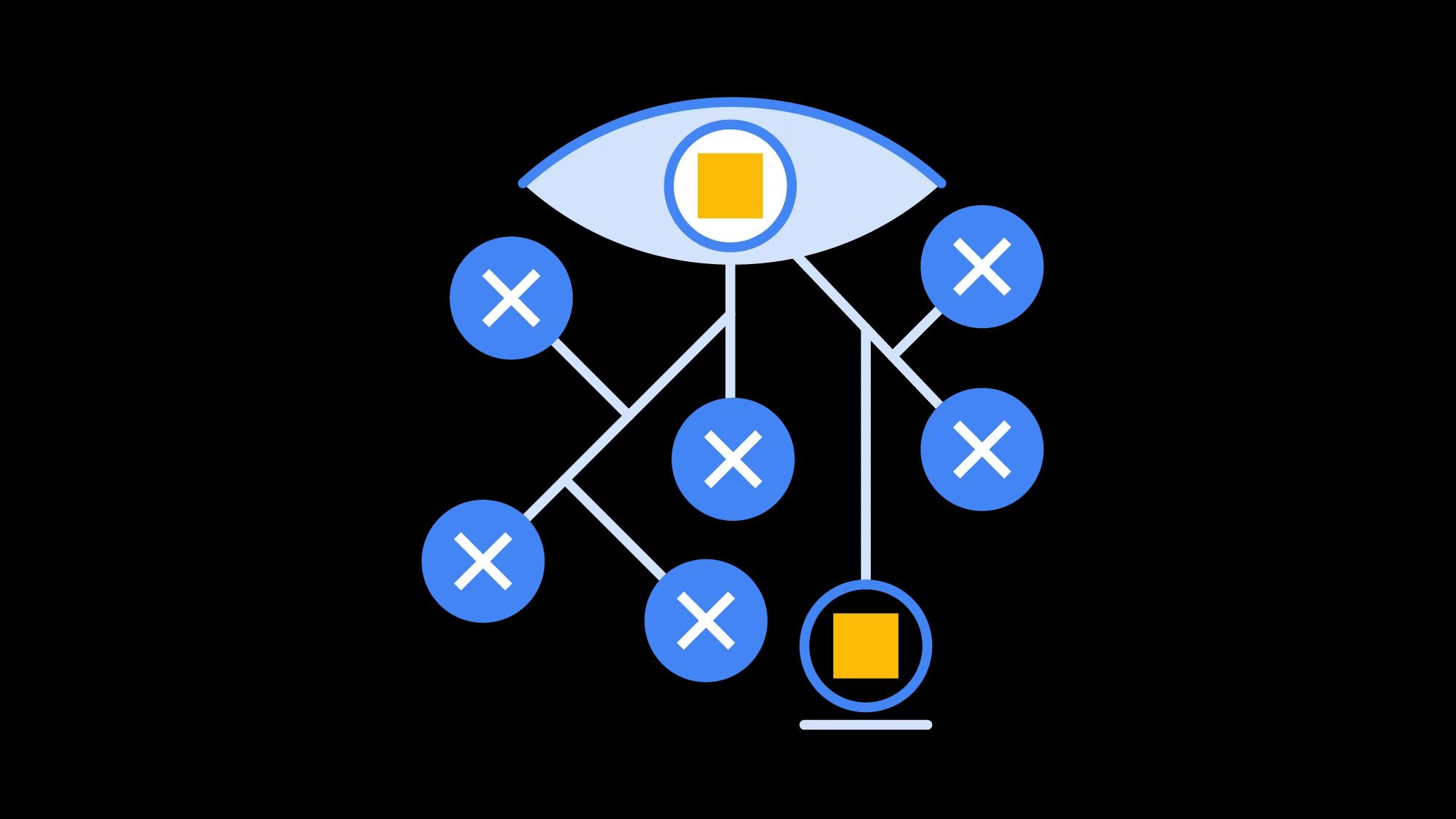
Classification
A task in which a model must predict what specific known group(s) a new input might belong to.
To help keep your Gmail inbox clean and your data safe, an ML model works in the background constantly classifying each email as spam or not spam (and if there’s any doubt, Gmail will ask you to verify the email address of an unknown sender). Binary predictions like this are great for resolving yes or no questions, but classification models can do much more. These models can predict multiple categories for a given input. Such a model may classify an email not only a “not spam,” but also as “important,” with the labels “finance” and “follow-up.” To learn more about how classification works and how versatile it can be, demo our What-If Tool. The What-If Tool is an interactive data visualization that helps teams analyze the results of ML models without writing any code.

Regression
A task in which a model must predict a numerical value for a specific scenario.
When you look up the price of a flight two weeks from today, a model is performing what’s called a “regression” task. For this user experience, the ML model must give you more than a discrete, yes/no type of response. To provide more nuanced information, the prediction is based on past data, in the form of continuous numerical values.
Imagine you have the task of designing a display of winter accessories in a store. Think of the task of classification as sorting winter accessories into neat bins, like sorting hats in one and scarves in another. This exercise would consider each accessory’s shape and other factors you and your store’s customers use to recognize what’s a scarf and what’s a hat. Think of a regression task as designing a complex window display with practical winter outerwear ensembles customized to your store’s snowy location. You want to include scarves and hats, as well as other items such as earmuffs, socks, fleece layers, and coats that you adjust based on the current weather, your past knowledge of what your customers need and want during this season, and the year’s fashion trends.
Regression predictions are used with a lot of versatility and inventiveness, powering incredibly complex user experiences that are capable of predicting changes in currency values, ranking songs to create a personalized playlist, or even determining image quality. When deciding if a regression model is appropriate for your users, a good place to start is the desired level of nuance and complexity in the final product or service. For a deeper example, learn how the Google Clips team used a regression model to build a hands-free camera.

Confidence level
A numerical expression of certainty in percentages.
When humans try to guess how old someone is, they say something like “I think this person may be 35 years old.” We know it’s only a guess, because phrases like “I think” and “may be” communicate a lack of confidence or certainty. Similarly, think of the predictions made by models as educated approximates, with a dash of uncertainty. The model’s level of certainty (or uncertainty, if you’re a glass-half-empty type of person) is expressed as a percentage, as in “I am 73.3% confident that this person is 35 years old.” The confidence level is used by product teams in deciding an acceptable response. So if a model is 70% confident that it will rain today, it’s worth recommending that our users have umbrellas handy.