
Simulating Intelligence
Techniques for prototyping machine learning systems across products and features
In the early days of any product cycle—for everything from a small tweak in an established app to a shiny, new product—uncertainty often runs rampant. Doubts about product reach, impact, and engineering effort get amplified when working with new technologies like machine learning (ML). However, there’s good news: exploratory prototyping can help. By building quick, real-feeling (and often wholly simulated) versions of products and features, teams can be nimble, explore various directions, fail early, and pivot repeatedly—all before going too far through the entire costly, messy ML development process.
What to prototype, and when?
When we talk about prototyping here, we mean creating a rapidly-built, probably not-meant-for-production-use approximation of a future product or feature. We do this to accelerate our ability to validate product market fit, explore feasibility, and learn from the product’s users. For example, if a planned feature would normally take six months to research, design, build, and test, that’s five-and-a-half months too late to find out that the idea is flawed in the first place. Perhaps it didn’t consider bias or address inclusivity concerns, or simply just doesn’t feel useful to the target audience. A good prototype gives you a shortcut to rapidly test your assumptions with your users, and to course-correct incrementally as you go.
Prototyping can be a great way to answer any number of questions (not just for ML), but before you dive into the deep end, you need to know the question you’re trying to answer. It can be as broad as “Does anyone find this useful?” or as tactical as “What happens with this feature with different users?” Once you have your question nailed down, you can start to gauge the fidelity and tools needed to answer it.
As a general rule of thumb, the fidelity of the prototype should match the fidelity of the problem. While the questions and ideas are still broad, low-fidelity options are often the best. Even (or especially!) for machine learning, creating wireframes and lightweight prototypes using tools like ProtoPie, Figma, or even paper, can be the best place to start. As your ideas solidify, you can increase the depth of your tech stack.
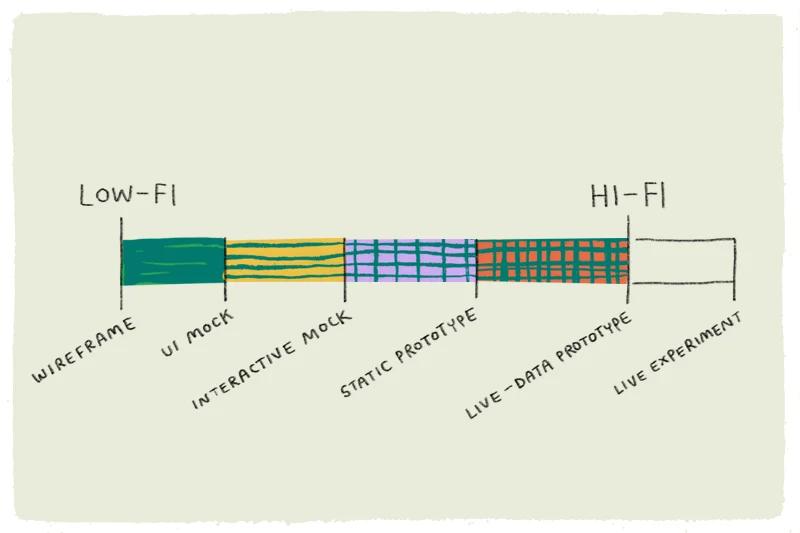
Should we do this? Early-stage prototyping
At this stage in the game, your goal is to minimize investment in the prototype, while maximizing learnings for your team:
- Don’t build things that are unrelated to the feature or workflow you want to test with users. Simulate whole sections of the UI, or skip showing them entirely—focus only on getting user feedback on one specific thing, and make that feel as real as you need to.
- Use off-the-shelf tools or ready-built design systems with code libraries, like Material, to get to a user-testable prototype as quickly as possible.
- Need data storage? Favor existing solutions like Firebase (or even spreadsheets, depending on what you’re doing).
And in the world of ML, where data collection and model training can take an enormous amount of time and resources, use humans in the place of not-yet-developed machine learning systems to validate ideas.
Example: Prototype for personalization
One common use for ML is personalization: creating systems that can give users personalized recommendations for everything from playlists to groceries. To build those systems, teams need deep technical infrastructure, sophisticated ML models (for things like natural language processing, speech recognition, or knowledge graph construction), carefully managed data sets, and answers to a whole host of questions on user privacy and preferences.
To build a convincing personalization prototype, you need a way to create a convincing version of the end user experience. There’s a super lightweight methodology used extensively by Google User Experience Engineers (UXEs) called Wizard of Oz. You create a real-looking version of the experience, and use humans in place of a fully-functional system.
For example, in personalized recommendation experiments, user researchers can ask study participants to share information about their preferences (music, destinations, or organic blueberries) to pre-populate screens and data with optimal choices. In real time, researchers then direct participants to complete specific scripted tasks. As this is happening, assistants can rapid-fire customize the prototype UI and/or responses, so that participants can test it with “personalized” recommendations. Presto! Instant personalization for user feedback without having to engineer the whole system.

This is only one method of prototyping—and there are many others. You can create more-functional, but tighter-scoped versions of features and test those, test various versions of answers and UIs, or build full-on approximations of the product—always aiming to limit the technical investment to match the study’s needs.
You will want to work shoulder-to-shoulder with your product, design, research, and engineering partners throughout this process. You can test a range of visual elements as designers iterate, garnering rich user feedback across a range of possible personalized experiences, and answering research questions while continuing to minimize overall investment. Then, guided by your research findings, you can collaborate with product and engineering teams to get these user-validated features ready for production.
Could we do this? Later-stage prototyping
Once you’ve confirmed through early concept prototyping that the direction is sound, there are still lots of technical questions for the team to answer, including some that are very specific to machine learning, such as:
- Can the team create a model that can reach the accuracy needed to meet the user needs? (Remember, these systems are predictive and often improve over time.)
- Where did the data used to train the model come from? Are there any biases in that data that the team needs to mitigate?
- What kinds of errors does the model typically make, and how can you offer users a path forward when they encounter them?
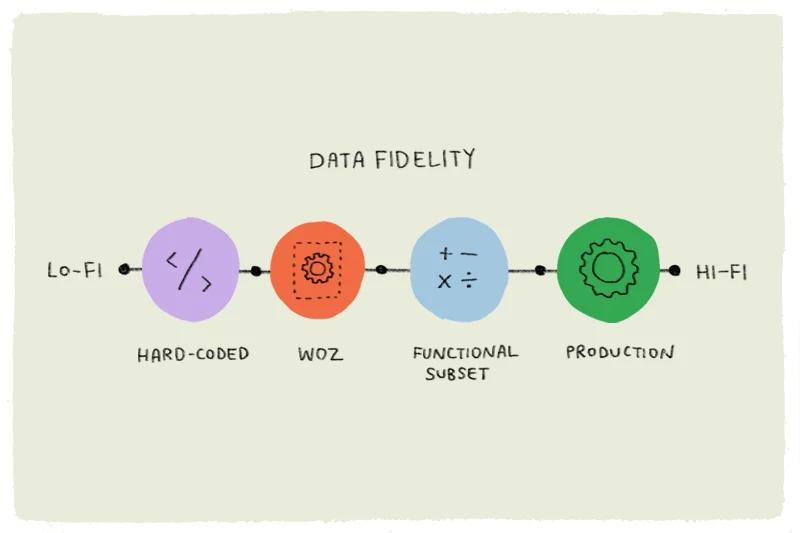
To answer these questions, you’ll need to build a prototype that comes as close as possible to the technologies you’ll use in production. You have a few options:
- Lean on prototype-friendly ML-powered frameworks like Teachable Machine to build real models that you can utilize in your higher-fidelity prototypes.
- Use command line scripts, or a manually-executed workflow, to provide real-feeling results for your user-testable UI (again, cut every corner that doesn’t directly help test the feature or concept at hand).
- Develop a very basic UI supporting a production-focused live model (to get feedback on how the system will act in real life).
Google UXEs have built a wide range of prototypes to answer these sorts of questions, utilizing a combination of the above approaches, and they’ve uncovered critical insights for both teams and products. Sometimes you realize that the current technology can’t actually do what you hoped it would (“We can’t reliably tell the difference between those two plants yet”), the team catches seemingly innocuous errors (“Why did that vision model label my desk as a bobsled?”), or you catch huge privacy or human-centered concerns that haven’t been discovered yet.
When our teams were building what would become the AIY Projects Vision Kit, we knew we wanted to pre-load the included Raspberry Pi with a bunch of demos to give people a starting point from which to build their own awesome projects. As with all good open-source projects, strong documentation was going to be key for its success—it needed to be easily understood and largely self-explanatory for a variety of users.
One of the included demos was an image classifier trained on the ImageNet dataset, designed to identify 1,000 different types of objects. When a user started the demo and pointed the camera at an object, they could see a list of what the model guessed it was seeing. In early testing, we found it did that well—but it would also produce some interesting side-effects.
If the object a user meant to classify was not the primary object in the frame, the demo might list out other things it was finding that the user wasn’t expecting (like the table the target object was sitting on). In addition, it would also identify things that weren’t actually there—it might be convinced that it had found a bobsled in a meeting room, for example. These results were not generally problematic (assuming there were bobsleds in conference rooms are a non sequitur at worst and hilarious at best), but it became clear that addressing this was going to be important for a good user experience.
When we released the final documentation, we had to be sure all this was taken into account. Explaining not only how the demos worked, but guiding users on how to use their kits to get the best results, turned out to be a key part of making the Vision Kit a success.
However you choose to build it, the goal here is to not only see what users will want it to do, but to ensure that it can actually do what they’re asking, and do so reliably. Will it work for all people, of all backgrounds, in all the scenarios you aim to support? Are the results what your team would expect, and have you built ways for users to respond and recover when the results are incorrect? This is the time to work all that out—the more you can validate your concerns and catch problems here, the smoother the product experience will be for everyone after launch.

What have we learned?
Building a prototype won’t instantly lead to absolute certainty, but it can help your team better understand your users, the product, and how the two best fit together. In addition, you’re likely to find problems you’ve never considered, as well as opportunities that wouldn’t have presented themselves otherwise. In the still-fresh world of developing machine learning solutions, these learnings can help save you time and money, learning faster while reducing the landscape of unknowns.
Whenever your team finds themselves unsure of what direction to pursue next, brainstorm ways of simulating the idea, and start testing it out for yourself. Once your team better understands both problem and solution, put your prototype in front of users. Repeat this process, refining and raising the level of fidelity as you go, and soon you’ll arrive at a solution that works better for everyone involved.