First: Raters
Designing for AI’s unseen users can lead to better products in the long run
Last year, I joined a Google Brain research team that applies machine learning (ML) to the world of healthcare. This team works on developing new tools and technologies that leverage ML to make medical services, like identifying symptoms, more accurate and accessible. It’s a new, rapidly evolving space, but I tried to approach my UX work just as I would on any other project. I mapped critical user journeys, made storyboards, and conducted interviews with clinicians, all in an attempt to solve core user needs.
Turns out I was a bit short-sighted. Even if you’re following a good design process when working with ML products, if you’re only focusing on the end users of the final product, you’re skipping over another, equally important group. I learned this lesson when a program manager approached me for guidance a couple months back. “I know you do design,” she said. “So maybe you can help me work out how to explain some new guidelines to my raters?”
Raters are the people who teach machines to learn. As opposed to the end users that designers often think about, raters are the equally important “starting” users.
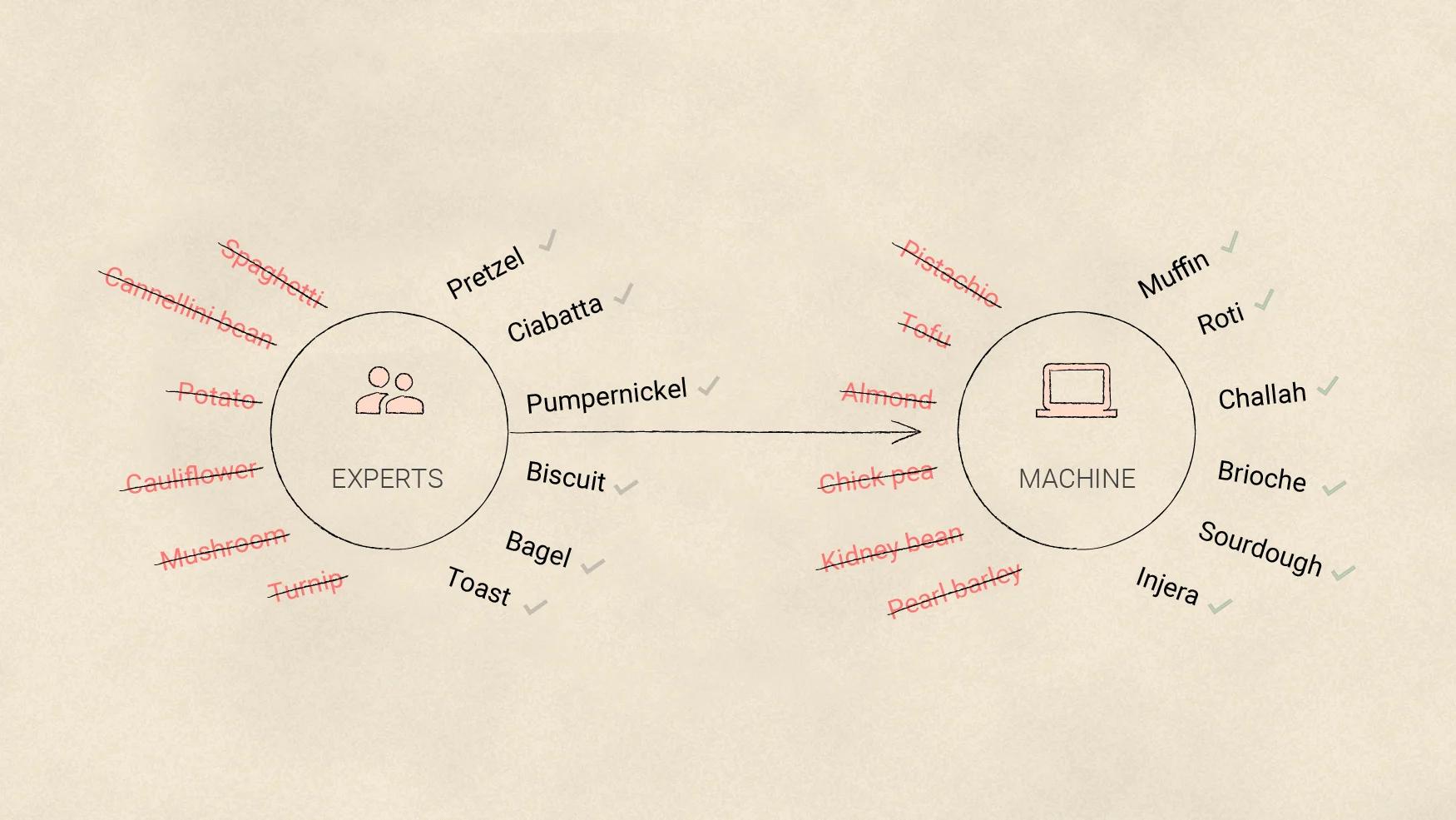
Raters tell a machine what to include and what to overlook so it can properly identify things on its own. In the example above, the machine might learn to identify types of bread (pretzel, ciabatta, pumpernickel, and so forth) from other similar-looking foods.
Raters come from a variety of backgrounds, and we recruit them in relation to the problem we’re trying to solve. Typically those problems are generic enough to recruit anyone to help. You’ve probably acted as a rater yourself: Every time you identify store signs in an image grid reCAPTCHA, you’re helping train machines. Increasingly though, we need to bring in the pros who are subject matter experts. To train a camera to take good pictures, the Google Clips team learned from real photographers. To accurately diagnose eye diseases, the Google AI Healthcare team consulted ophthalmologists.
Raters are required to follow certain rules on how to share their knowledge with the machine. For photography, that might mean agreeing that a ‘bad’ picture is one that’s out of focus or one in which someone blinked. When the raters are consistent, the machine learns faster.
Let’s say we want to teach machines to suggest the best ice cream flavor based on a person’s preference. Raters might review transcripts of customers deciding what to buy in an ice cream store and do the following three things:
The machine can then learn from these data points to start making its own recommendations.
Getting everyone to highlight, label, and group consistently is no easy task, so we created guideline rulebooks to help. Raters reference this rulebook while using our team’s simple software tool that helps them log their highlights, labels, and groups.
Imagine that the tool showed customer-feedback transcripts from ice cream stores. Raters would first check the guidelines for what to note in the transcripts. Then, raters highlight the parts of the transcript where the customers says something relevant.
For example, if the transcript reads: “Sea salt caramel is the creamiest!” the rater might scroll over the term “sea salt caramel” to highlight it as a flavor and then scroll over “creamiest” and highlight it as a descriptor. Then, the raters group those notes together so the machine learns first: Sea salt caramel is a type of flavor, and second: One reason it’s popular is that it’s so creamy.
Let’s go back to my UX work on the Google Brain team, keeping this hypothetical example in mind. I listened to the program manager detail the latest set of guidelines for our raters, and I realized that they were indeed complex. The raters had over 40 pages of guidelines! Design-wise, that’s a challenge.
A significant portion of the training focused on how to deal with the limitations of the simple software tool the Google Brain team was using to annotate and mark up the transcripts. What it didn’t include was sufficient keyboard shortcuts to help the raters move fast and stay efficient. Accidental errors were hard to spot and unfortunately easy to submit in the software. Even worse, because of the poor UX, it was impossible to undo a change. These factors made every edit feel like a monumental commitment.
Couldn’t we just change the raters’ annotation tool so their job is easier? I quickly realized the reason it hadn’t been changed was actually because of me. I hadn’t given the raters’ experience with the tool any thought at all. I'd spent months on the team at that point, 100 percent focused on the final product and not the raters. I presented decks, made demo videos, and thought through user journeys as I anticipated the future demands of our yet-to-be product. But what good was all that if the tool our raters were using to build the model, wasn’t scaling to their needs?
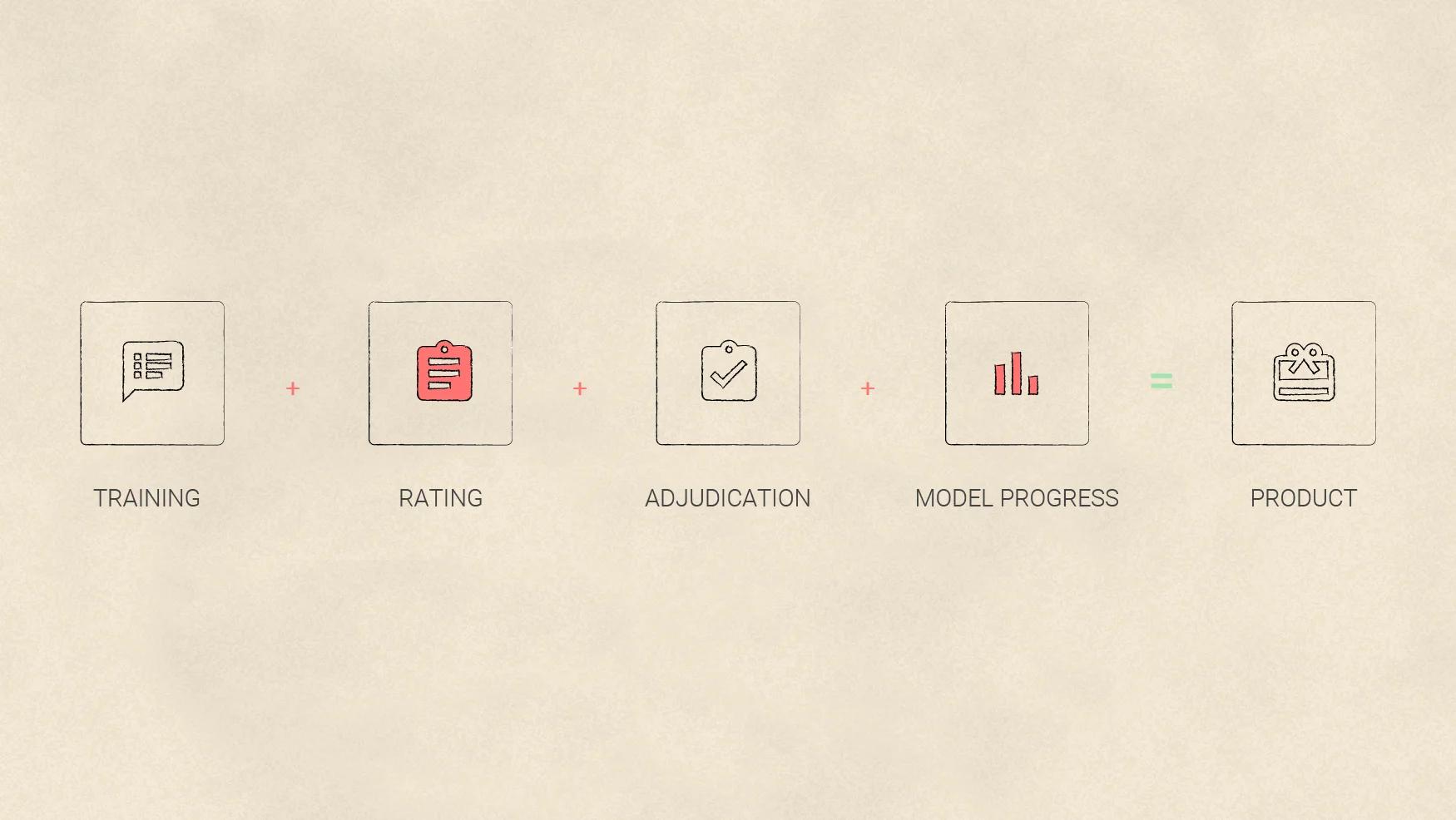
Designers are trained to focus on the final product, but ML projects require a set of pre-release processes that need our attention, too. Human raters must be taught a set of guidelines, use rating tools, and reconcile grading differences, all before a product is ready to launch.
It was time to talk with all users. Not just the potential end users of the non-existent final product, but the real, sitting-in-my-cubicle-space users who had been quietly dealing with the tool’s limitations for too long.
Why didn’t the raters ask for help sooner? The training guidelines were long (over 40 pages) and looked official. Certainly a lot of thought had been put into the process, including the raters’ annotation tool itself. It worked great for its intended use of simple phrase selection, but as the team grew and the inputs to teach the model became more complex, no designer had revisited the core flows to see whether they were holding up.
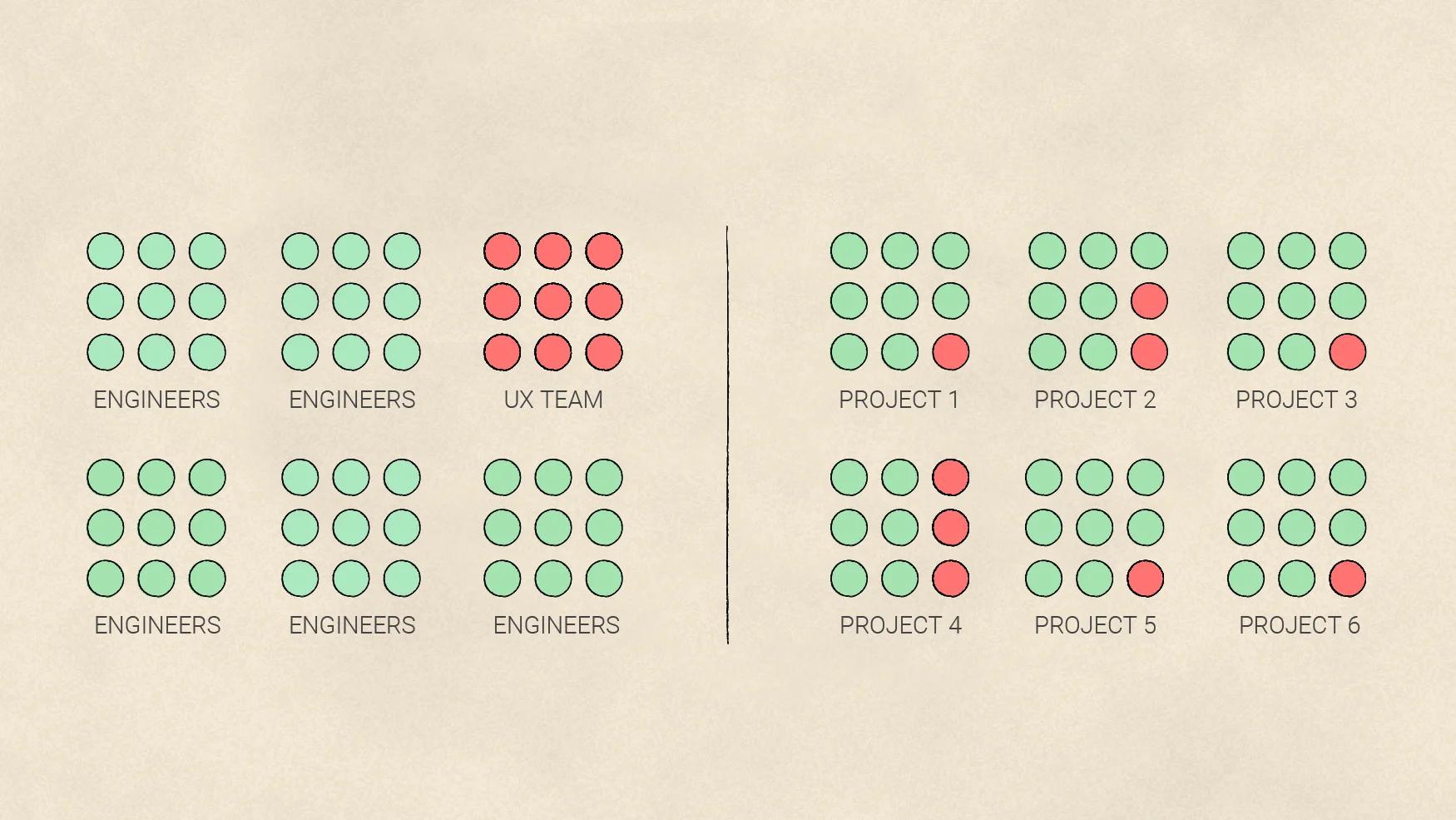
UX teams often sit in their own hub (as shown above, left), which is useful, but it separates them from the engineers implementing their work. Colocating engineers and UX designers (as shown above, right) by project aids collaboration.
Raters often work remotely (because they're usually freelancers). Within my specific team at Google Brain, however, a number of raters sit just a few feet away from my desk. I realized I could easily peer over these raters’ shoulders as they used their annotation tool, studying firsthand how they worked through the key flows in the tool’s interface. So I decided to conduct a usability test with our raters, asking them about workarounds and prodding them for pain points. Together, the raters and I drafted a list of prioritized solutions for where the tool was falling short.
It took about a month for engineers to fix the most critical needs, which included implementing keyboard shortcuts, editing features, and error warnings. As the engineers announced each change, the raters lit up with appreciation. To outsiders, the small UX tweaks might seem trivial, but for the raters, the changes vastly simplified their workflow. This was evident in metrics too: The error rate decreased by 96 percent.
Lessons learned: Four tips to use when designing for raters
Simplifying raters’ workflow is essential for efficiently training ML models. The UX tweaks we made for raters as described above are a start, but my team at Google Brain is still in the early stages of building our own tool for labeling data. Here are a few things the team has learned so far about designing for rating.
1. Use multiple shortcuts to optimize key flows
Raters regularly use keyboard shortcuts to move between lines, select text, and assign labels. It’s a testament to the original engineer of the raters’ annotation tool that no one ever complained about the word selection function. It’s always been a slick process, automatically selecting the entire word for faster highlighting.
When you start providing multiple ways for raters to complete a task, consider asking them for ideas. For example, they helped us identify that grouping text highlights was a helpful action. After a long day of manual grouping, one of our raters had the brilliant idea to select a paragraph of text and use a keyboard shortcut to automatically group all highlights within the selected region. That saved her from having to individually select each highlight to group them, which shaved useful seconds off the task.
2. Always provide easy access to labels
A typical dropdown menu might seem like the most obvious way to let raters label a highlighted phrase with tags, but it isn’t. Let’s go back to our ice cream store example. Imagine a rater highlighting “sea salt caramel,” then clicking on a drop-down menu with more labels to describe the ice cream as “creamy.” Dropdown menus are helpful for the first label, but not for subsequent labels. In studies with our rater annotation tool, raters complained that the menus, represented by text boxes that offered choices for additional labels, covered up existing labels on the screen. Obscuring the screen made it difficult for raters to see the additional context they needed from the text.
We decided to redesign the menu so when raters select a highlight, the dropdown menu of labels opens in the margins of the screen. As raters add labels, they still appear below highlighted text, but are no longer covered up by a dropdown. This helped raters confirm which labels were already linked to words before adding more.
3. Let raters change their minds
I learned from studying the behaviors of raters that they don’t do their work in a set sequential order. When reviewing text, they might highlight words and label them as they go, or they might make it through a couple paragraphs, see the topic shifted, then go back and put similar highlights into groups. If they’re reviewing images, they might skip a few tough ones and go back to them later. Any two raters might frequently disagree and need to have a conversation about how to reconcile their choices.
Raters need a flexible workflow and tools that support editing and out-of-sequence changes. One way to do this is to create text fields outside the main body, much like the ‘comment’ dialogs in Google Docs that show up in the margins and clearly reference highlighted text. This allows raters to leave notes on their progress or remember questions for later reference.
It’s also important to ensure that raters can discuss their choices and make the changes needed to align with each other. Supporting methods of offline discussion, such as shared commenting on the file itself, helps raters resolve disagreements more quickly.
4. Auto-detect and display errors
It’s not fair to ask raters to simply “do their best” to meet a rule set for any given project. Build the rules into the tool so it’s visually clear when errors are present. For example, we contemplated showing alerts for important errors or blocking submissions until they’re fixed. Instead, we settled for an auto-prompted “error list” raters must check before submitting. It lets raters know when errors are detected but avoids the potential annoyance of pop-up alerts. Since setting up this list, the number of submissions with errors dropped precipitously, and we don’t have as much throwaway data.
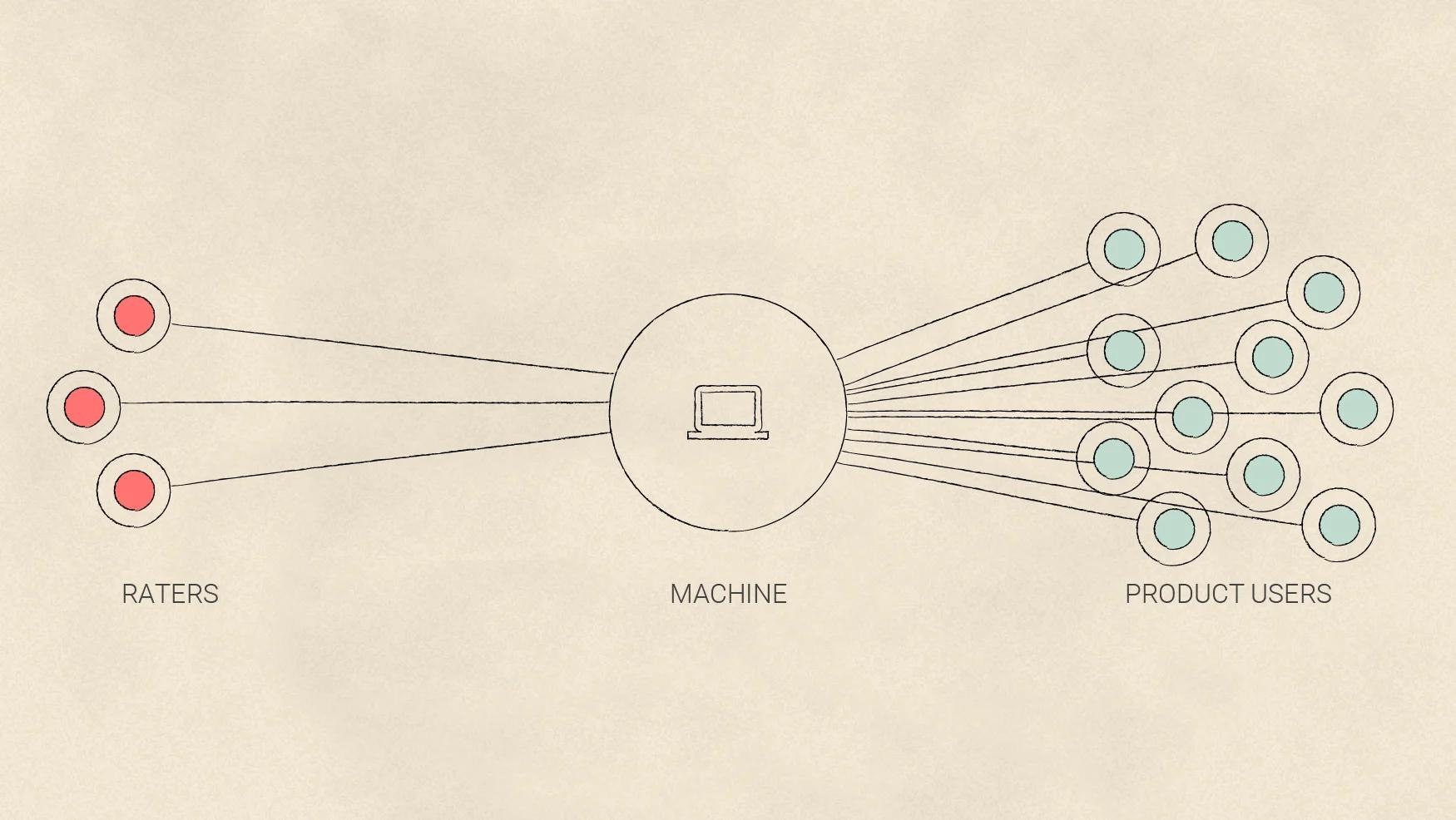
A small number of raters can have a large impact on the final product. Think of them as your users, too.
Designers play an instrumental role in shaping the working environment for raters. It’s important as UXers to help raters do their best work by finding ways to optimize flows, start and stop tasks, change their minds, and above all, not lose context. When you create the best teaching environment for raters, the machine will learn more quickly and with better accuracy. We remember the good teachers in our lives for a reason. When it comes to designing for ML-applied products, first look to your raters. They lay the foundation for how the rest of us will experience AI in the future.
Prior to joining the Google Research team, Rebecca Rolfe spent three years as a designer for Chrome and worked previously as a graphics journalist. She is a graduate of the Digital Media master's program at the Georgia Institute of Technology.
For more on how to take a human-centered approach to designing with ML and AI,visit our collectionof practical insights from Google's People AI + Research team.