
Fair Is Not the Default
Why building inclusive tech takes more than good intentions
This essay was adapted from a TEDx talk by the same name, and has been edited and revised by the author.
In an otherwise lovely photo of a crowd in Venice’s San Marco Square (see image, below), there's something curious going on if you look a little closer. Everyone's head falls roughly along the same horizon line. Now that’s odd. Everyone in the world isn’t the same height, right? This optical illusion occurs because the photographer was of average height. From the perspective of an outlier, someone of not-so-average height, the world would look far less uniform.

A photo of a crowd in San Marco Square, Venice. The horizon line is highlighted to illustrate that the height of the people in the crowd appears to be relatively uniform. Source: Nino Barbieri, Creative Commons.
{kind=link}
I’m a designer at Google who works on products powered by AI—artificial intelligence or AI is an umbrella term for any system where some or all of the decisions are automated. And for the last year or so, I've been helping lead a company-wide effort to make fairness a core component of the machine learning process. What do I mean by machine learning, and what do I mean by fairness? Machine learning is the science of teaching computers to make predictions based on patterns and relationships that've been automatically discovered in data. And speaking more personally, fairness comes down to two fundamental beliefs: A product that’s designed and intended for widespread use shouldn’t fail for an individual because of something they can’t change about themselves; technology should work for everyone.
While these don’t seem like a controversial opinions, when we look at the history of traditional product design, it’s littered with examples of people making decisions that don’t work for everyone, and are instead in line with defaults—the things that go without saying; the obvious; the status quo.
The problem with designing for defaults
Take for example the way we test automotive safety in the United States. Until 2011, it wasn’t mandatory to perform front-impact collision testing using a crash test dummy with a female body type. As a result, before this date, women were 47 percent more likely to be severely injured in car crashes. And even now, crash test dummies only represent the fifth percentile for female height and weight, and two out of three frontal-impact tests don’t put them in the driver’s seat.

Several “Shirley cards” from the 1960s and 1970s. The nickname “Shirley” applied to all the models Kodak used for color standardizing negatives, which notably only featured white women with long hair.
In the 1960s and 1970s, “Shirley cards” were the standard for how photographers in the US performed color calibration. The idea is that when processing a photo you tried to get the colors in the provided swatch to render accurately without messing up Shirley’s complexion, after which—in theory—future photos would also develop accurately. But you've probably spotted something amiss. Until relatively recently, Shirley cards only featured white women with long hair.
But change didn't come because someone recognized how unrepresentative this process was, or by looking at the obvious disparity in white balance and exposure between people with pale and dark skin (like the one below on the left). Instead, change came to the consumer market with Kodak Gold in 1995, but only after chocolate companies and wood furniture manufacturers complained to Kodak about the limited spectrum of brown visible in print advertisements.
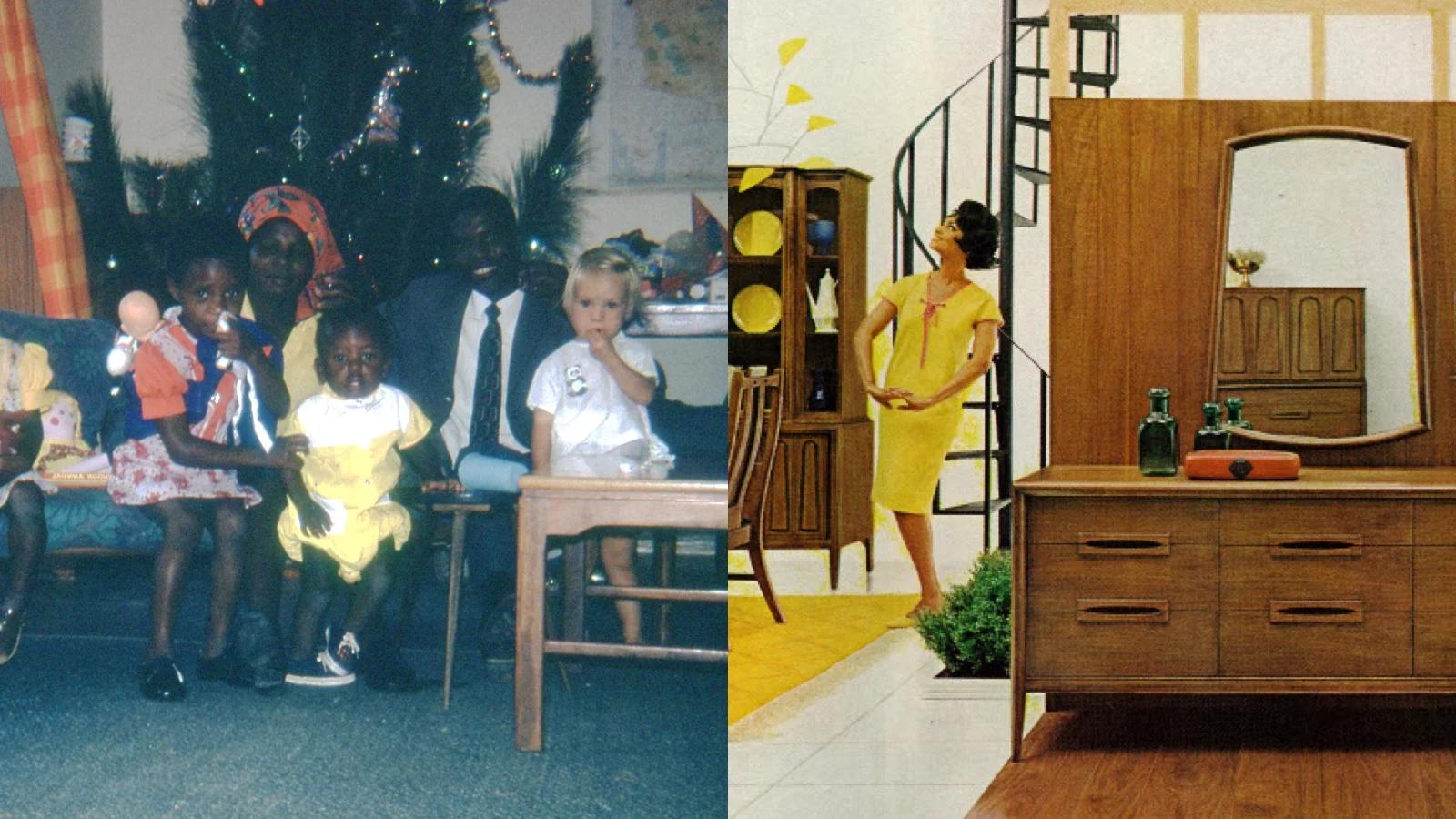
On the left, a 1970s-era photo demonstrates the disparity in film performance for people with darker skin tones. On the right, an advertisement in a furniture magazine from around the same time, also demonstrates a rather lackluster spectrum of brown. Source (left to right): Walt Jabsco, Creative Commons, Classic Film, Creative Commons
In the film industry, we start to see how machine learning can help raise awareness about gaps in representation. Fellow Googler Hartwig Adam worked in collaboration with the Geena Davis Institute for Gender in Media, to analyze every frame from the top 100 grossing films over each of the last three years. Using a technique called classification, they compared the frequency that women and men appeared. The result: men are seen and heard nearly twice as often as women.
So where are these disconnects coming from? Are car companies intentionally trying to hurt women? Was the decision to color balance for light skin overtly racist? Are movie directors, producers, and writers trying to marginalize women on purpose? I choose another answer. I believe these were the behaviors of rational actors making what they perceived to be obvious decisions, because they were in line with defaults. Let's review one more example.
A Cornell University study performed in the late seventies—and reproduced a number of times since (1983, 1986, 2000, 2015)—asked participants to rate an infant’s emotional response after watching a video of the baby interacting with a number of different stimuli. Half the participants were told the child was a boy, and the other half that it was a girl. When the child smiled or laughed, participants agreed universally that the infant’s dominant emotion was joy. But when the child interacted with something jarring, like a buzzer or a jack-in-the-box, there was a split. If a participant had been told the child was a girl, they thought her dominant emotion was fear. But if they'd been told the child was a boy, participants thought the dominant emotion was anger. Same child, same reaction, different perception.

The singular difference of a child’s gender has significant impact on our interpretation of their emotions.
Most people would probably agree that it’s irrational behavior to treat an angry person the same way we would treat a fearful one. But perception isn’t rational. Our read of another person’s emotional state is mostly a jumble of lived experiences and cultural reference points. And signals get crossed all the time in unexpected ways. We might even judge someone to be less caring or generous simply because their hands were cold. And it’s our perceptions that drive virtually every facet of machine learning.
Data and human judgment
When the machine learning process is represented visually, it’s often depicted as a complex array of nodes, strung together into a sufficiently impressive-looking decision tree (see image below). But let's unpack that a bit.
A typical representation of a neural network, shows criss-crossing lines connecting layers of “neurons,” and leads to a final layer with a single neuron highlighted, to signify a prediction output.
Imagine a teacher compiling a reading list for her students. She wants them to grasp a certain concept which is expressed in different ways in each of the books. Simply memorizing the various answers won’t result in any practical knowledge. Instead, she expects her students to discover themes and patterns on their own, so they can be applied more broadly in the future.
The majority of machine learning starts much the same way, by collecting and annotating examples of relevant real-world content (this is called “training data”). Those examples are then fed into a model that’s designed to figure out which details are most salient to the prediction task it’s been assigned. As a result of this process, predictions can be made about things the model has never seen before, and those predictions can be used to sort, filter, rank, and even generate content.
It’s easy to mistake this process for an objective or neutral pipeline. Data in, results out. But human judgment plays a role throughout. Take a moment to consider the following:
- People choose where the data comes from, and why they think the selected examples are representative.
- People define what determines success, and further, what evaluation metrics to use in measuring whether or not the model is working as intended.
- People are affected by the results.
Machine learning isn’t a pipeline, it’s a feedback loop. As technologists, we’re not immune to the effects of the very systems we’ve helped instrument. The media we get exposed to daily—including the way it’s been ranked, sorted, filtered, or generated for us—affects the decisions we’ll make, and the examples we’ll draw from, the next time we set out to build a model.
Considering the flaws in human perception, and the kinds of of less-than-ideal product decisions like those detailed in this article, one of the conclusions people often jump to is that we need to remove human judgment from the process of machine learning. “If we could just get rid of these pesky human emotions,” what a wonderfully efficient world it could be.
Let’s look at another example. In 2016, a company called Northpointe developed software to predict the likelihood that defendants would re-offend if granted parole. When all other criteria were equal, the singular difference of race dramatically boosted the risk score of blacks over whites, often by more than double. The company claimed that they didn’t use race as a feature in training their model, but unfortunately this notion of data “blindness” actually makes the problem worse. Given the nature of deep learning, and the sheer amount of information a model is exposed to, it’s all but guaranteed that proxies for race (like income or zip code, attributes that are highly correlated to race in the United States) will be automatically discovered and learned.
A particularly awkward example came from FaceApp, an app that allowed users to take a selfie and turn on a “hotness” filter. But it often just made people look whiter (it’s since been disabled). This is an example of what can happen when a model is trained with skewed data—in this case, social media behavior from predominantly white countries.
Another example caused quite a stir in the research science community early last year. Two researchers from China claimed to have trained a model that—using only a headshot photo—could predict whether someone was a criminal with almost 90 percent accuracy. There were a number of methodological issues with their approach. For example, the number of examples in their data set was rather limited, and they had no way to know for sure whether the people they labeled as ‘“non-criminals” had ever committed a crime and just never got caught. But on a deeper level, their approach assumes that there are people who are born criminals. If there are any patterns to discover in this case, they’re not about the judgement of individuals, but rather those who’re doing the judging.
There’s no silver bullet. Fairness is contextual and uniquely experienced by every individual. So when we set out to build technology for humans, using human data, we need to plan for how we’ll respond when—not if—bias manifests in some unwanted way. Removing yourself from the process and trusting in the myth of neutral technology isn’t enough, so I propose that we instead make machine learning intentionally human-centered and that we intervene for fairness.
One size(almost) never fits all
When we run focus groups, we joke that it's only a matter of seconds before someone mentions Skynet or The Terminator in the context of artificial intelligence. As if we'll go to sleep one day and wake up the next with robots marching to take over. Few things could be further from the truth. Instead, it’ll be human decisions that we made yesterday, or make today and tomorrow that will shape the future. So let’s make them together, with other people in mind.
We need to be skeptical of the myths that we tell ourselves, and I’m not just talking about science fiction. We tell ourselves the myth that justice is blind, yet black Americans are arrested at four times the rate of white Americans on drug-related charges, despite equal rates of use. We tell ourselves the myth that tests like the SATs reflect academic ability, but they don’t actually predict academic achievement. We tell ourselves the myth that personalized medicine is working for everyone, yet the majority of experimental participants are white and male. And we tell ourselves the myth that the “crowd” is always a reliable source of truth.

An early version of the AI-powered game Quick, Draw! didn’t perform as well at recognizing certain shoe styles, because early users drew sketches that looked like Chuck Taylor Converse (above, left) more often than other shoe types, like high heels (above, right).
The game “Quick, Draw!” developed through Google’s AI Experiments program is a good example of why it’s critical to engage with a diversity of perspectives when testing a product. In the game, people were asked to draw pictures of everyday things like shoes to train a model. Most early users drew shoes that looked like sneakers, so as more people interacted with the game, the model wasn’t able to recognize any type of shoe that wasn't a sneaker. With these findings in-hand, the team was able to intentionally seek out additional training examples to compensate for gaps in representation, and performance improved dramatically. We’ve open-sourced the Facets visualization tool so that more people can apply this kind of inclusive lens to assessing their data for unwanted homogeneity.
Designing for fairness means confronting inequality in the world while maintaining an open and curious mind. It starts with asking questions: Who am I? And how can I better understand the needs of everyone else?

There are so many unique combinations of facial characteristics. Simple categories never tell the whole story.
I have many traits that would be considered defaults in today’s tech industry. I’m white. And I’m a cisgendered man, with a partner of the opposite sex. But I also have traits that are outside of the norm. I’m very tall, for one. I’m also legally blind, and as a Jew, I grew up in a cultural minority.
We’re each complex individuals—our traits don’t define us, but it would foolish to pretend others don’t see them. By taking the uncomfortable step to inventory our own traits—physical, social, cognitive, and otherwise—we can better connect with the experience of being made to feel like an outsider, when a default that doesn’t match up with our identity is invoked in day-to-day life. For many people, this kind of exercise isn’t a choice.
We all share the desire to belong. To just be ‘us’ without having to bear the burden of someone else’s preconceptions. By taking stock in our assumptions about values and goals, we can start to make room for more voices in the discussion. And hopefully in the process, we can learn to see the world as less binary: people like me, and people not like me. And instead, see it as a world of intersectionality, where we celebrate our differences as opportunities for greater understanding. And in so doing, to harness machine learning to its full potential as a tool to help us seek out patterns in the world—especially at the margins. A tool that can enrich human connection and augment human capability; a tool for explorers; to help us see beyond the defaults.
For more on how to take a human-centered approach to designing with ML and AI, visit our full collection.